서론

핀터레스트에서 검색을 할 때 이미지를 넣어서 유사한 핀을 찾을 수 있는 기능이 있다. 구글 렌즈와 유사한 기능이다.
과연 어떻게 이미지로 이미지를 찾을 수 있는 것인지, 이번 글에서는 이에 대해 작성해보고자 한다.
초기 이미지 검색
AI/ML이 발전하기 전, 초기에는 어떻게 이미지를 비교할 수 있었을까?
픽셀 비교의 한계
이미지는 무수히 많은 픽셀로 구성된다. 그리고 이 픽셀은 각각 RGB 3개의 숫자로 표현된다. 빨간 픽셀은 -> (255, 0, 0) 이런식이다.

귀여운 고양이 사진이 3만개의 픽셀로 이루어져있다고 해보자. 이를 통해서 비슷한 고양이 사진을 찾으려고 한다. 3만개의 픽셀의 값을 모두 비교해서 가장 유사한 사진을 찾는 방식으로 찾을 수 있을 것이다.
하지만 이는 여러 문제점이 있다. 우선 모두 계산을 해야하기 때문에 비효율적이다. 더욱 치명적인 것은, 동일한 고양이 이미지여도 위치가 살짝이라도 다르면 각 픽셀의 값이 모두 변한다는 것이다.
즉, 인간이 보기에는 거의 동일한 이미지여도 픽셀 값은 완전히 다르기 때문에 찾을 수가 없다.
CNN의 탄생
CNN은 Convolutional Neural Network의 약자로, 합성곱 신경망이라고 불린다.
Neural Network(인공 신경망)는 인간의 뇌에서 뉴런이 작동하는 방식을 본떠 만든 하드웨어 및 소프트웨어 시스템이다. 일반적으로 CNN(합성곱 신경망)은 완전히 연결 또는 풀링된 여러 합성곱층에서 다양한 다층 퍼셉트론(시각적 입력을 분류하는 알고리즘)을 적용한다.
CNN은 픽셀 값을 직접 비교하지 않고, 이미지에서 패턴을 찾아내는 방식으로 접근한다. 어떻게 패턴을 찾아나가는 것인지는 아래 내용에서 이어진다.
CNN: 이미지에서 패턴 찾기
인간의 시각 피질(Visual Cortex)
시각 피질이란, 인간의 뇌에서 시각 정보를 처리하는 대뇌 피질의 영역이다. 인간이 무엇인가를 인식할 때는 여러 번의 층을 거친다.
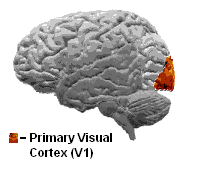
- 망막을 통해서 빛을 전기 신호로 변환해 뇌로 전달한다.
- V1 영역에서 선, 엣지를 감지한다.
- V2, V4 영역에서 텍스처, 형태를 감지한다.
- IT 피질에서 “이게 고양이다” 최종 인식한다.
CNN도 이와 유사하다. 여러 층을 거치며 이미지의 패턴을 찾고, 최종적으로 이미지의 특징을 압축한 숫자 배열(벡터)을 출력한다.
학습 과정에서도 재미있는 특징이 있다. 갓 태어난 아기는 고양이를 알지 못 한다. 자라면서 고양이를 눈으로 여러 번 보게 되고, 여러 요소의 특정 모양과 색상을 배우게 된다. 발과 몸통, 귀, 털의 색상 등 여러 정보들을 인식할 수 있게 되면 그제서야 고양이와 새를 구분할 수 있게 된다. 이는 CNN 모델이 학습하는 과정과 굉장히 유사하다.
필터
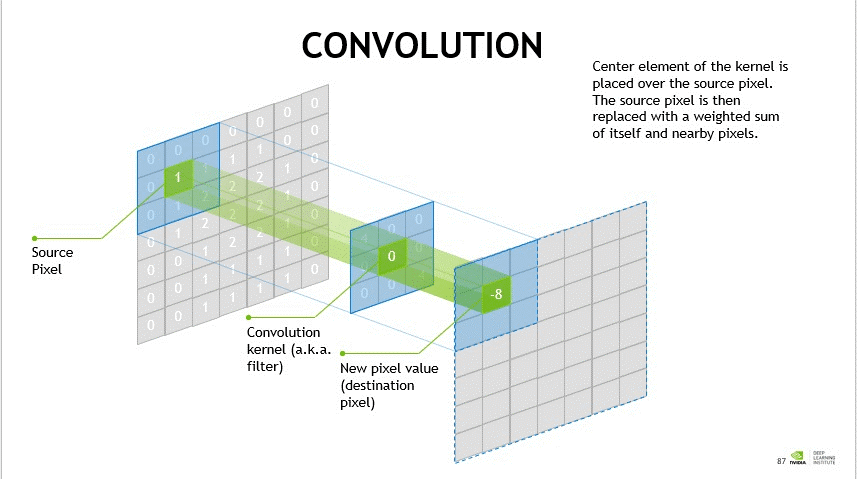
필터는 딱 한 가지만 검사하는 검사관이라고 보면 이해가 쉽다. 마치 공장에서 불량품을 검수할 때, 각자 맡은 부분이 정해져 있는 것처럼 말이다.
어떤 검사관은 세로선이 있는지, 어떤 검사관은 동그라미가 있는지만 본다. 검사관은 이미지를 왼쪽 위부터 한 칸씩 훑으며 자리마다 점수를 매긴다. (3x3 크기로 점수를 내는 방식이 일반적이라고 한다.)
3x3 크기의 검사판이 존재하고, 칸마다 다른 가중치를 가지고 있다. 이러한 가중치의 조합이 특정한 패턴을 의미한다.
본인이 찾는 모양이 뚜렷하면 높은 점수, 없으면 낮은 점수를 매긴다. 그래서 세로선 검사관이 고양이 사진을 다 보고 나면, 다리 윤곽처럼 세로선이 있는 자리만 점수가 높아 환하게 도드라진 그림이 한 장 나온다.
이런 검사관을 패턴마다 수십~수백 명 두는데, 한 명이 한 가지 패턴씩 맡는다. 그래서 검사관 수가 곧 그 층이 찾아내는 패턴의 가짓수다.
같은 검사관이 이미지 전체를 훑기 때문에, 고양이가 왼쪽에 있든 오른쪽에 있든 똑같이 찾아낸다. 앞서 픽셀 비교의 치명적인 약점이었던 “위치가 조금만 바뀌어도 못 찾는 문제” 가 여기서 해결된다.
층이 쌓일수록 추상화된다
필터 하나로는 선이나 색 같은 단순한 정보밖에 잡지 못 한다. CNN은 층을 마치 레고처럼 계속해서 쌓아가며 결과를 도출해낸다.
작은 블록(선, 엣지)을 모으면 모양(눈, 귀)이 되고, 모양을 모으면 고양이 얼굴이 된다. 첫 번째 층이 찾아낸 결과(=아웃풋)를 다음 층이 다시 재료(=인풋)로 쓰면서, 한 단계씩 더 큰 의미로 합쳐 올라가는 것이다.
이건 앞에서 언급한 시각 피질의 처리 순서와 매우 유사하다.
- 첫 층 → V1 : 선, 엣지
- 중간 층 → V2, V4 : 텍스처, 모양
- 마지막 층 → IT 피질 : “이건 고양이다”
즉, 층이 깊어질수록 모델이 보는 것은 낱낱의 픽셀에서 점점 추상적인 의미로 올라간다.
마지막 층의 출력 - 임베딩 벡터
이 과정을 끝까지 통과하면, CNN은 이미지 한 장을 숫자 몇백 개짜리 배열 하나로 압축해서 내놓는다. 이걸 임베딩 벡터(embedding vector)라고 부른다.
임베딩 벡터는 이미지의 지문 같은 것이다. 위치·크기·배경이 조금 달라도, 내용이 비슷한 이미지는 비슷한 지문이 나온다.
임베딩 벡터가 이미지로 이미지를 찾는 핵심 기술이 된다. 3만 개의 픽셀을 일일이 비교하는 대신, 이미지마다 이 지문을 미리 뽑아두고 지문끼리만 비교하면 되기 때문이다.
마무리
- 픽셀을 그대로 비교하는 방식은 비효율적이고, 위치만 살짝 바뀌어도 무너진다.
- CNN은 필터(검사관) 로 패턴을 찾고, 이를 레고처럼 쌓아 의미로 추상화한다.
- 최종적으로 이미지를 임베딩 벡터(지문) 로 압축하고, 픽셀이 아닌 이 지문을 비교해 비슷한 이미지를 찾는다.
CNN과 인간의 시각 피질이 유사하다는 점이 흥미로웠다. 현대 기술의 상당히 많은 부분들을, 인간 또는 자연에서 찾아볼 수 있는 것 같다. 2편에서는 이미지와 텍스트를 같은 공간에 두는 기술들에 대하여 알아보도록 하겠다.