📌 hashCode
Java에서의 해시 코드는 객체를 해시 기반 자료구조에서 효율적으로 관리하기 위해 생성되는 정수 값이다.
일반적으로는 해시 코드 자체가 겹치는 경우는 자주 발생하지 않으나, 그렇다고
해시 코드가 고유하다라고 말할 수는 없다.
이번 글에서는 이에 대해서 정리해보려고 한다.
📌 hashCode가 고유하지 않은 이유
1. hashCode는 32비트 int 값이다
Java에서의 hashCode는 int 정수형으로 생성된다. 때문에 값의 범위는 약 -21억 ~ +21억으로 약 43억 가지가 나올 수 있다.
즉, 무한하지 않은
유한한 값이라는 것이다.
단순하게 JVM 내 객체 수가 이보다 많을 수 있으며, 수많은 서로 다른 객체가 이 43억 가지 hashCode 값 중 하나에 매핑되므로 충돌은 수학적으로 필연적이다.
해싱의 세계에서는 이를 비둘기집 원리(Pigeonhole principle) 로 설명할 수 있다.
다른 객체임에도 해시 코드가 동일한 경우를
해시충돌이라고 부르며, 이러한 충돌을 최소화 하는 해시 함수를 만드는 것이 중요하다.
비둘기집 원리
비둘기집 원리란, N개의 비둘기 집에 M마리의 비둘기를 넣으려고 할 때 M > N이면 어떤 비둘기 집에는 필연적으로 비둘기가 2마리 이상 들어간다는 수학적인 원리이다.
즉, 11마리의 비둘기를 10개의 집에 넣으려고 할 때 아무리 잘 분배하더라도 1개의 집에는 2마리 이상의 비둘기가 들어가게 되는 것이다.
hashCode를 int형으로 만든 이유?
해시 코드를 int가 아닌 long으로 반환하면 해시 충돌이 더 줄어들지 않을까? 왜 int 형으로 만든 것일까?
결론부터 말하면 long으로 만든다고 해서, 효율성이 높아진다고 보장할 수 없다. 이유는 아래와 같다.
해시 기반 컬렉션의 효율성
HashMap, HashSet, Hashtable같은 자료구조들은 내부적으로버킷이라는 개념을 사용하는데, 이는배열로 구현되어 있다.- 배열의 인덱스를
hashCode % capacity(배열 size)같은 방식으로 계산한다. - Java에서의 배열 크기는 int형으로 제한되어 있다.
- 때문에 만약 해시 코드가 long이라면, 인덱스를 계산할 때 추가 연산(long → int 변환 등)이 필요해 효율성이 오히려 떨어질 수 있다.
메모리 효율
- 지금과는 다르게, 1990년대 초반 Java 설계 당시에는 메모리와 CPU 비용에 훨씬 민감했다.
- 만약 long(64비트)을 hashCode로 쓰면 해시 테이블 내부에서 long 연산이 많아지고, 필요 이상 큰 값으로 index를 만들기 때문에 낭비가 심해져 int로 정하게 되었다.
2. hashCode는 메모리 주소 기반이 아니다
만약 hashCode == 메모리 주소 였다면, 이는 객체마다 다른 고유한 값이 맞으므로 해시 코드가 고유할 수도 있겠다.
하지만 hashCode는 객체의 메모리 주소와 다르다. JVM 내부 구현 방식에 따라 다르겠지만, 현재는 대부분 메모리 주소와 전혀 관련이 없다.
또한 메모리 주소를 기반으로 해시 코드를 만들었다 하더라도, 객체 개수가 43억 개를 넘어간다면 비둘기집 원리에 의해서 충돌이 필연적으로 발생한다.
📌 테스트
import java.util.ArrayList;
import java.util.List;
public class HashCodeCollisionTest {
public static void main(String[] args) {
List<Integer> seenHashCodes = new ArrayList<>();
int collisionCount = 0;
int maxAttempts = 1000000;
for (int i = 0; i < maxAttempts; i++) {
Object obj = new Object();
int hashCode = obj.hashCode();
if (seenHashCodes.contains(hashCode)) {
collisionCount++;
System.out.println((i + 1) + "번째 시도");
System.out.println("충돌 hashCode: " + hashCode);
System.out.println();
} else {
seenHashCodes.add(hashCode);
}
}
if (collisionCount == 0) {
System.out.println("충돌이 발생하지 않았습니다. (시도 수: " + maxAttempts + ")");
} else {
System.out.println("총 충돌 발생 횟수: " + collisionCount);
}
}
}
새로운 객체를 만들고, 리스트에 넣은 후 동일한 해시 코드가 이미 존재한다면 출력하는 형태로 테스트를 진행하였다.
원래는
HashMap, HashSet를 활용하려 했는데, 이는 해시 컬렉션이라 -> 해시코드 자체로만 비교하는 것이 아니라 내부적인 해시 테이블 상에서 충돌이 발생하기 때문에ArrayList를 사용하였다.
결과
...
987463번째 시도
충돌 hashCode: 1999539787
993518번째 시도
충돌 hashCode: 1845922248
994245번째 시도
충돌 hashCode: 1479783205
994730번째 시도
충돌 hashCode: 2063331329
총 충돌 발생 횟수: 2321만, 10만 번 까지는 충돌이 발생하지 않았으나, 100만 번으로 횟수를 늘리니 충돌 횟수가 현저하게 늘어났다.
📌 hashCode가 고유하지 않아도 괜찮은 이유
여기까지 Java에서의 해시 코드는 고유하지 않음을 알아보았다. 고유하지 않다면 다른 객체임을 확인할 수가 없게 될텐데, 문제가 발생하지는 않을까?
설계적으로 hashCode 충돌을 허용한다
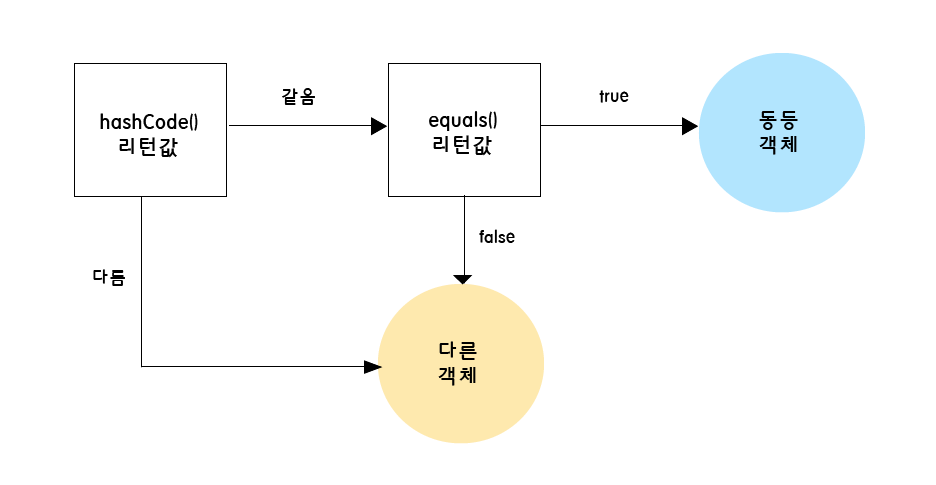
해시 컬렉션에서 동등 객체를 판별할 때, 위와 같은 로직을 거친다.
- 해시 코드가 같은가?
- equals()가 true인가?
즉, 다른 객체끼리 같은 해시 코드를 가지게 되더라도, equals()에서 false가 나오게 되므로 문제가 발생하지 않는 것이다.
물론, 해시 코드 자체로만 비교를 하는 경우가 있다면 문제가 발생할 수 있으나, 이는 흔치 않다.
Java의 hashCode() 설계 원칙
“equals가 같으면 hashCode도 같아야 하지만, equals가 다르면 hashCode는 같을 수도 있다.”
즉, 충돌은 이미 예상된 상황이며, equals()로 최종 구분하도록 설계되어 있다.
중요한 것은 충돌을 최소화 하는 방법(좋은 해시 함수 등)과 해시 충돌이 발생했을 때 효율적으로 대처하는 방법일 것이다.
다음 글에서는 해시 충돌에 대해서 다루어보려고 한다.