📌 서론
Java에서 Object 클래스의 hashCode() 메서드를 호출하게 되면, 일반적으로는 객체의 메모리 주소나 그 주소를 기반으로 계산한 수치를 해시 코드로 반환하게 된다.
(hashCode() 메서드에 대해서는 해당 글에 정리해두었다.)
여기서 중요한 점은 hashCode() == 메모리 주소 가 아니라, 해시 코드는 객체의 메모리 주소 or 주소를 기반으로 계산한 수치 라는 것이다.
그러나 이에 대해서 혼동하는 사람들이 많고, 실제로 관련한 많은 정보들이 인터넷 상에 있기 때문에 이번 글을 통해서 사실 유무를 확인해 보려고 한다.
사용 Java 버전 : OpenJDK17
📌 JVM에서의 hashCode() 기본 동작
Object.hashCode()
@IntrinsicCandidate
public native int hashCode();Object 클래스의 해시 코드 메서드이다.
이는 일반적인 메서드와 다르게, native 메서드이기 때문에 JVM 내부(네이티브 코드) 에 구현되어 있다.
JNI(Java Native Interface) 를 통해 JVM 레벨, 시스템 레벨에서 작동하는 구조이다.
그렇기에 이는 JVM에 의존하는 동작이며, 내부 구현 방식이 JVM의 버전에 따라 달라질 수 있다는 의미가 된다.
📌 hashCode()와 메모리 주소 비교
예시 코드를 통해서 hashCode()와 실제 메모리 주소를 비교해 보자.
예시
import org.openjdk.jol.vm.VM;
public class Test {
public static void main(String[] args) {
Object obj = new Object();
// hashCode 출력
int hashCode = obj.hashCode();
System.out.println("obj.hashCode(): " + hashCode); // 2060468723
// identityHashCode 출력
int identityHashCode = System.identityHashCode(obj);
System.out.println("System.identityHashCode(obj): " + identityHashCode); // 2060468723
// 메모리 주소 출력 (JOL 사용)
long address = VM.current().addressOf(obj);
System.out.println("Memory address: " + address); // 30331364672
// toString 확인
System.out.println("obj.toString(): " + obj.toString()); // java.lang.Object@7ad041f3
// hashCode 16진수 변환
System.out.println("hashCode in HEX: " + Integer.toHexString(hashCode)); // 7ad041f3
}
}
hashCode와identityHashCode는 동일하다.
- 재정의하지 않은, Object 클래스의 기본 메서드를 사용했기 때문에 identityHashCode()와 동일한 값이 나오게 된다.
hashCode와메모리 주소는 동일하지 않다.
2060468723와30331364672- 숫자만 보아서는 유사성을 알아차리기가 힘들다.
toString()에서@뒤에 나오는 값과,hashCode를 16진수로 변환한 값은 동일하다.
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}- 이는 Object 클래스에서의 toString() 메서드가 그렇게 구현되어있으므로 당연한 결과이다.
여기까지 알게 된 사실은 다음과 같다.
hashCode()와toString() @ 이후의 값은 사실상 같은 값이다.hashCode()와객체의 메모리 주소는 동일하지 않다.
hashCode() 주석 살펴보기
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@link
* equals(Object) equals} method, then calling the {@code
* hashCode} method on each of the two objects must produce the
* same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link equals(Object) equals} method, then
* calling the {@code hashCode} method on each of the two objects
* must produce distinct integer results. However, the programmer
* should be aware that producing distinct integer results for
* unequal objects may improve the performance of hash tables.
* </ul>
*
* @implSpec
* As far as is reasonably practical, the {@code hashCode} method defined
* by class {@code Object} returns distinct integers for distinct objects.
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/
@IntrinsicCandidate
public native int hashCode();Object 클래스의 hashCode() 메서드에 있는 주석을 살펴보면 많은 정보를 얻을 수 있다.
- 같은 객체에 대해 여러 번 호출하면 같은 값을 반환해야 한다. (단, equals에 사용되는 값이 변하지 않을 때)
- equals가 true인 두 객체는 hashCode도 같아야 한다.
- equals가 false인 두 객체는 hashCode가 다를 필요는 없지만, 다르면 성능이 좋다.
- Object.hashCode는 가능한 한 서로 다른 객체에 대해 서로 다른 값을 반환하도록 한다.
여기서는 메모리 주소와 관련한 내용은 없지만, 이보다 하위 JDK 버전에서는 기재된 경우도 있는 듯하다.
OpenJDK JVM의 hashCode()
그렇다면 실제로 어떠한 로직을 통해서 JVM은 해시 코드를 생성하고 있는지 알아보자. JVM 내부는 대부분 C++로 구현되어 있다.
서론에서 말했듯이 OpenJDK 17 버전을 사용하였다.
JVM_ENTRY
JVM_ENTRY(jint, JVM_IHashCode(JNIEnv* env, jobject handle))
// as implemented in the classic virtual machine; return 0 if object is NULL
return handle == NULL ? 0 : ObjectSynchronizer::FastHashCode (THREAD, JNIHandles::resolve_non_null(handle)) ;
JVM_END
JVM_ENTRY매크로는Object.hashCode()호출을 JVM 내부의JVM_IHashCode네이티브 함수에 연결해 준다.
handle == NULL이면 0 반환, 아니면FastHashCode를 통해 해시코드를 계산한다.
JNIHandles::resolve_non_null(handle)는 JNI 핸들을 실제 객체 참조로 변환한다.
ObjectSynchronizer::FastHashCode
intptr_t ObjectSynchronizer::FastHashCode(Thread* current, oop obj) {
if (UseBiasedLocking) {
// NOTE: many places throughout the JVM do not expect a safepoint
// to be taken here. However, we only ever bias Java instances and all
// of the call sites of identity_hash that might revoke biases have
// been checked to make sure they can handle a safepoint. The
// added check of the bias pattern is to avoid useless calls to
// thread-local storage.
if (obj->mark().has_bias_pattern()) {
// Handle for oop obj in case of STW safepoint
Handle hobj(current, obj);
if (SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::revoke_at_safepoint(hobj);
} else {
BiasedLocking::revoke(current->as_Java_thread(), hobj);
}
obj = hobj();
assert(!obj->mark().has_bias_pattern(), "biases should be revoked by now");
}
}
while (true) {
ObjectMonitor* monitor = NULL;
markWord temp, test;
intptr_t hash;
markWord mark = read_stable_mark(obj);
// object should remain ineligible for biased locking
assert(!mark.has_bias_pattern(), "invariant");
if (mark.is_neutral()) { // if this is a normal header
hash = mark.hash();
if (hash != 0) { // if it has a hash, just return it
return hash;
}
hash = get_next_hash(current, obj); // get a new hash
temp = mark.copy_set_hash(hash); // merge the hash into header
// try to install the hash
test = obj->cas_set_mark(temp, mark);
if (test == mark) { // if the hash was installed, return it
return hash;
}
// Failed to install the hash. It could be that another thread
// installed the hash just before our attempt or inflation has
// occurred or... so we fall thru to inflate the monitor for
// stability and then install the hash.
} else if (mark.has_monitor()) {
monitor = mark.monitor();
temp = monitor->header();
assert(temp.is_neutral(), "invariant: header=" INTPTR_FORMAT, temp.value());
hash = temp.hash();
if (hash != 0) {
// It has a hash.
// Separate load of dmw/header above from the loads in
// is_being_async_deflated().
// dmw/header and _contentions may get written by different threads.
// Make sure to observe them in the same order when having several observers.
OrderAccess::loadload_for_IRIW();
if (monitor->is_being_async_deflated()) {
// But we can't safely use the hash if we detect that async
// deflation has occurred. So we attempt to restore the
// header/dmw to the object's header so that we only retry
// once if the deflater thread happens to be slow.
monitor->install_displaced_markword_in_object(obj);
continue;
}
return hash;
}
// Fall thru so we only have one place that installs the hash in
// the ObjectMonitor.
} else if (current->is_Java_thread()
&& current->as_Java_thread()->is_lock_owned((address)mark.locker())) {
// This is a stack lock owned by the calling thread so fetch the
// displaced markWord from the BasicLock on the stack.
temp = mark.displaced_mark_helper();
assert(temp.is_neutral(), "invariant: header=" INTPTR_FORMAT, temp.value());
hash = temp.hash();
if (hash != 0) { // if it has a hash, just return it
return hash;
}
// WARNING:
// The displaced header in the BasicLock on a thread's stack
// is strictly immutable. It CANNOT be changed in ANY cases.
// So we have to inflate the stack lock into an ObjectMonitor
// even if the current thread owns the lock. The BasicLock on
// a thread's stack can be asynchronously read by other threads
// during an inflate() call so any change to that stack memory
// may not propagate to other threads correctly.
}
// Inflate the monitor to set the hash.
// An async deflation can race after the inflate() call and before we
// can update the ObjectMonitor's header with the hash value below.
monitor = inflate(current, obj, inflate_cause_hash_code);
// Load ObjectMonitor's header/dmw field and see if it has a hash.
mark = monitor->header();
assert(mark.is_neutral(), "invariant: header=" INTPTR_FORMAT, mark.value());
hash = mark.hash();
if (hash == 0) { // if it does not have a hash
hash = get_next_hash(current, obj); // get a new hash
temp = mark.copy_set_hash(hash) ; // merge the hash into header
assert(temp.is_neutral(), "invariant: header=" INTPTR_FORMAT, temp.value());
uintptr_t v = Atomic::cmpxchg((volatile uintptr_t*)monitor->header_addr(), mark.value(), temp.value());
test = markWord(v);
if (test != mark) {
// The attempt to update the ObjectMonitor's header/dmw field
// did not work. This can happen if another thread managed to
// merge in the hash just before our cmpxchg().
// If we add any new usages of the header/dmw field, this code
// will need to be updated.
hash = test.hash();
assert(test.is_neutral(), "invariant: header=" INTPTR_FORMAT, test.value());
assert(hash != 0, "should only have lost the race to a thread that set a non-zero hash");
}
if (monitor->is_being_async_deflated()) {
// If we detect that async deflation has occurred, then we
// attempt to restore the header/dmw to the object's header
// so that we only retry once if the deflater thread happens
// to be slow.
monitor->install_displaced_markword_in_object(obj);
continue;
}
}
// We finally get the hash.
return hash;
}
}FastHashCode() 는 Object.hashCode() 의 네이티브 레벨 구현으로, 객체의 hashCode 값을 다음 중 하나로 반환한다.
- 이미 생성되어
객체 header/monitor에 기록된 hash
- 새로 생성한 hash (충돌 방지, 동기화 보장)
1. Biased Locking 상태 체크
if (UseBiasedLocking) {
if (obj->mark().has_bias_pattern()) {
// Bias lock 해제
Handle hobj(current, obj);
if (SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::revoke_at_safepoint(hobj);
} else {
BiasedLocking::revoke(current->as_Java_thread(), hobj);
}
obj = hobj();
assert(!obj->mark().has_bias_pattern(), "biases should be revoked by now");
}
}💡 객체가 bias locking 상태면 bias를 해제 → hashCode는 bias와 양립 불가.
biased locking (편향 락)?
- 락을 얻을 때 비용을 줄이기 위해 설계된 JVM 최적화 기법
- 동기화된 블록을 항상 같은 스레드가 사용할 때 락 자체를 생략(편향)하는 방식이다.
- 즉, 객체의
mark word에 락을 걸어둔 스레드 정보를 저장하고, 다른 스레드가 그 객체에 락을 걸기 전까진 락 경쟁 없이 그대로 사용한다. - 단일 스레드가 lock/unlock을 반복하는 경우, 락 오버헤드가 거의 0에 가깝기 때문에, JVM은 편향 락을 default on으로 두고 필요 시 revoke한다.
revoke?
revoke는biased lock을 해제하는 작업이다.- 객체가 biased 상태일 때, 다른 스레드가 접근하거나 / hashCode가 필요하면 bias를 해제하고 락을 일반 락으로 전환한다.
hashCode와 bias locking은 왜 양립 불가인가?
- JVM은 객체의
mark word라는 곳에 락 정보, hashCode, GC 정보 등을 저장한다.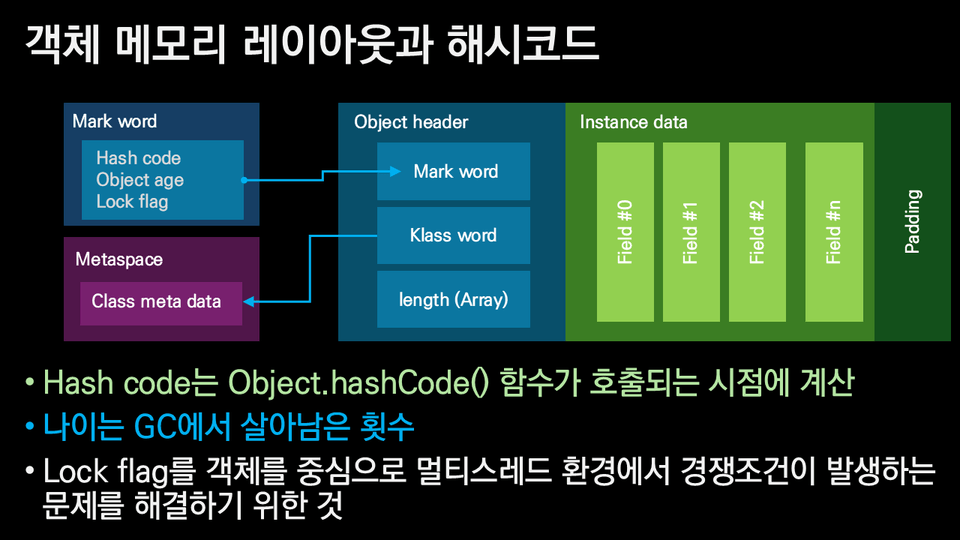
- hashCode()를 호출하면 같은 mark word에 해시 값을 기록해야 하는데, 이미 스레드 ID 등으로 공간이 차지되어 있어 쓸 수 없다.
- 따라서 둘을 동시에 유지할 수 없고, hashCode를 기록하기 위해 biased locking을 해제(bias revoke) 하게 된다.
💡 safepoint 여부에 따라 revoke 방식 결정.
safepoint?
- JVM에서 모든 스레드를 잠시 멈추고 특정 작업(GC, biased locking revoke 등)을 안전하게 수행하기 위한 시점이다.
- safepoint에서는 JVM 내부 구조 변경, 힙 검사, GC 작업 등을 수행할 수 있다.
2. 무한 루프 (hash 값 얻을 때까지 반복)
while (true) {
...
}💡 hash 값이 생성/설정될 때까지 여러 시도를 반복한다.
3. markWord 읽기
markWord mark = read_stable_mark(obj);💡 객체 header 중 일부인 mark word를 읽는 부분이다.
4. header 상태에 따른 처리
💡 (a) Neutral 상태 (lock 걸리지 않음)
Neutral 상태?
Java 객체의 mark word 내부 biased 상태 중 하나이다. Neutral은 객체가 락이 걸려 있지 않은 상태를 의미한다.
if (mark.is_neutral()) {
hash = mark.hash();
if (hash != 0) return hash;
hash = get_next_hash(current, obj);
temp = mark.copy_set_hash(hash);
test = obj->cas_set_mark(temp, mark);
if (test == mark) return hash;
}- 이미 hash가 있으면 반환한다.
- 없으면 새 hash를 생성한다. (get_next_hash)
CAS로 markWord에 기록 → 성공하면 반환한다.- 실패하면 다른 스레드가 기록했을 가능성 → 루프를 반복한다.
CAS?
CAS(Compare-And-Swap) 는 동시성 프로그래밍에서 원자적(atomic)으로 값 갱신을 보장하는 연산이다.
Java나 JVM 내부에서 락 없이 안전하게 데이터를 갱신하기 위해 사용되며, 특히 mark word나 객체의 상태를 업데이트할 때 많이 사용된다.
💡 (b) 이미 inflated (monitor 사용 중)
Inflated?
- inflated 상태는 객체가
monitor (ObjectMonitor)를 사용 중이라는 뜻 - 즉, 객체의 lock 상태가 경량 락(lightweight lock) 또는 bias 를 넘어 무거운(monitor) 락으로 승격된 상태이다.
- 아래의 경우에 Inflated 상태가 될 수 있다.
- lock 경쟁이 심해서 더 이상 경량 락으로는 동기화 유지가 어려움
- 특정 JVM 내부 동작 (예: hashCode 기록) 때문에 monitor가 필요함
이 경우 mark word에는 monitor의 주소가 저장된다.
Monitor?
monitor는 JVM 내부에서 락과 관련된 메타데이터를 담는 동기화 객체이다.C++의 ObjectMonitor 구조체로 구현되어 있다.- 아래의 정보들이 들어갈 수 있다.
- 락 소유자 정보
- 대기 큐 (다른 스레드가 이 객체의 락을 기다릴 때)
- displaced mark word (원래 mark word 복사본)
- hashCode (필요시 기록)
- 기타 상태 정보
monitor는 힙에 할당되며, mark word는 이 monitor의 주소를 가리킨다.
else if (mark.has_monitor()) {
monitor = mark.monitor();
temp = monitor->header();
hash = temp.hash();
if (hash != 0) {
if (monitor->is_being_async_deflated()) {
monitor->install_displaced_markword_in_object(obj);
continue;
}
return hash;
}
}monitor에서 hash 읽음 → 있으면 반환한다.deflation race발견 시 다시 루프를 반복한다.
Deflation race?
deflation은 사용하지 않는 monitor를 정리해 mark word를 원래 상태로 되돌리는 과정이다.deflation race는 monitor를 deflate (해제)하는 도중, 다른 스레드가 monitor 정보를 읽거나 쓰는 시점과 충돌(race condition)하는 상황이다.
때문에 deflation 중이면 mark word를 복원하고 루프를 돌며 다시 시도하게 된다.
💡 (c) stack lock 상태 (현재 스레드가 소유)
else if (current->is_Java_thread() && current->as_Java_thread()->is_lock_owned((address)mark.locker())) {
temp = mark.displaced_mark_helper();
hash = temp.hash();
if (hash != 0) return hash;
}- 스택 lock 상태라면
displaced markWord에서 hash를 확인한다. - 없으면
inflate필요 → race 방지.
5. monitor inflate 및 hash 설정
monitor = inflate(current, obj, inflate_cause_hash_code);
mark = monitor->header();
hash = mark.hash();
if (hash == 0) {
hash = get_next_hash(current, obj);
temp = mark.copy_set_hash(hash);
uintptr_t v = Atomic::cmpxchg((volatile uintptr_t*)monitor->header_addr(), mark.value(), temp.value());
...
return hash;
}monitor inflate→ 안정적 hash 기록 준비- hash 없으면 새로 생성 후
CAS로 기록한다.
Monitor inflate?
monitor inflate는 JVM이 mark word의 공간 대신ObjectMonitor 라는 별도 구조체(힙에 위치)를 생성하고 연결하는 작업을 말한다.- 이 과정을
inflate (팽창)라고 부르는 이유는, 단순 mark word → mark word + monitor 구조체 조합으로 관리 단위가 커지기 때문이다.
6. 최종 반환
위 모든 과정을 통해서 hashCode를 확보하고, 최종적으로 반환한다.
📌 오해가 생긴 이유?
여기까지 JVM 내부에서 hashCode를 어떻게 생성하는지까지 알아보았다. 로직을 보면 알겠지만, 객체의 메모리 주소를 이용하는 부분은 없었다.
그런데 왜 이런 오해가 있었던 것일까? 아래의 이유 정도가 있을 듯하다.
- toString() 출력값, 즉
@ 뒤 hashCode의 16진수가 메모리 주소처럼 보인다.
- 오래된 JVM 일부 옵션에서, 실제로 메모리 주소 기반으로 생성하는 경우가 있다.
- 문서나 강의에서 단순화하여 설명하였다.
identityHashCode == 메모리 주소라는 잘못된 이해가 있다.
여기서 2번에 주목할 만하다. 이에 대해서는 실제 코드로 살펴볼 수가 있다.
get_next_hash
ObjectSynchronizer::FastHashCode 에서 get_next_hash를 호출하는데 코드는 아래와 같다.
static inline intptr_t get_next_hash(Thread* current, oop obj) {
intptr_t value = 0;
if (hashCode == 0) {
// This form uses global Park-Miller RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random();
} else if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3;
value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
} else if (hashCode == 2) {
value = 1; // for sensitivity testing
} else if (hashCode == 3) {
value = ++GVars.hc_sequence;
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj);
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = current->_hashStateX;
t ^= (t << 11);
current->_hashStateX = current->_hashStateY;
current->_hashStateY = current->_hashStateZ;
current->_hashStateZ = current->_hashStateW;
unsigned v = current->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
current->_hashStateW = v;
value = v;
}
value &= markWord::hash_mask;
if (value == 0) value = 0xBAD;
assert(value != markWord::no_hash, "invariant");
return value;
}옵션 0
if (hashCode == 0) {
// 0️⃣ Park-Miller RNG
value = os::random();
}글로벌 난수 생성기(Park-Miller RNG) os::random()을 통해 전역 난수를 생성한다.- 여러 스레드가 동시에 접근하면 캐시 일관성(Coherency Traffic) 비용이 커질 수 있다.
- OpenJDK 6/7 기본값이다.
옵션 1
else if (hashCode == 1) {
// 1️⃣ 주소 기반 + stw_random
intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3;
value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
}객체 주소 일부 + XOR + STW 랜덤 방식으로, 객체 주소 비트를 시프트하고 XOR 연산하여 생성한다.GVars.stw_random은stop-the-world시점 난수로 GC 이후에도idempotent (멱등, 값 일관성 보장)하다.- 주소 기반 같아 보여도 메모리 주소를 직접 쓰진 않는다. (조합/연산 결과)
옵션 2
else if (hashCode == 2) {
// 2️⃣ 감도 테스트용 상수
value = 1;
}- 테스트용 상수로,
해시 값이 무조건 1이다. - 해시 충돌을 강제로 유발해서 해시맵, 해시셋 등의 충돌 처리 성능을 테스트할 때 사용할 수 있다.
옵션 3
else if (hashCode == 3) {
// 3️⃣ 순차 증가값
value = ++GVars.hc_sequence;
}- 글로벌 순차 ID 방식으로, 객체마다 순차적으로 증가하는 해시 코드이다.
- 충돌이 없고 순서가 보장되지만, 멀티스레드에서 CAS 비용이 존재한다. (여러 스레드가 동시에 증가시키려 할 수 있기 때문.)
옵션 4
else if (hashCode == 4) {
// 4️⃣ 메모리 주소 cast
value = cast_from_oop<intptr_t>(obj);
}- 객체 메모리 주소를 int로 변환하는, 메모리 주소 기반 hashCode 방식이다.
GC Compaction등으로 객체가 이동하면 주소가 바뀔 수 있어서 주의해야 한다.- 때문에 일반 JVM에선 디폴트 값이 아니며, 주소 기반 hashCode는 비추천된다.
객체 헤더
mark word내부에 해시 코드를 저장한다면 GC 작업이 이루어져 주소가 변경되어도 문제가 발생하지 않는다.
반면, 객체의 메모리 주소를 해시 코드로 활용한다면 GC Compaction 단계 등에서 영향을 받아 문제가 생길 수 있어 추천하지 않는 것이다.
옵션 5
else {
// 5️⃣ Marsaglia xor-shift
unsigned t = current->_hashStateX;
t ^= (t << 11);
current->_hashStateX = current->_hashStateY;
current->_hashStateY = current->_hashStateZ;
current->_hashStateZ = current->_hashStateW;
unsigned v = current->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
current->_hashStateW = v;
value = v;
}스레드 로컬 xor-shift 난수로,Marsaglia xor-shift 방식 난수이다.- 스레드 로컬 상태(_hashStateX 등) 기반으로, 빠르고 충돌이 적다.
- OpenJDK 8+ 디폴트이다.
📌 옵션 4로 테스트
실제로 옵션 4로 설정하고 해시 코드를 출력하면 어떻게 나올까?
시작에 앞서 인텔리제이에서 VM 옵션을 설정해준다.
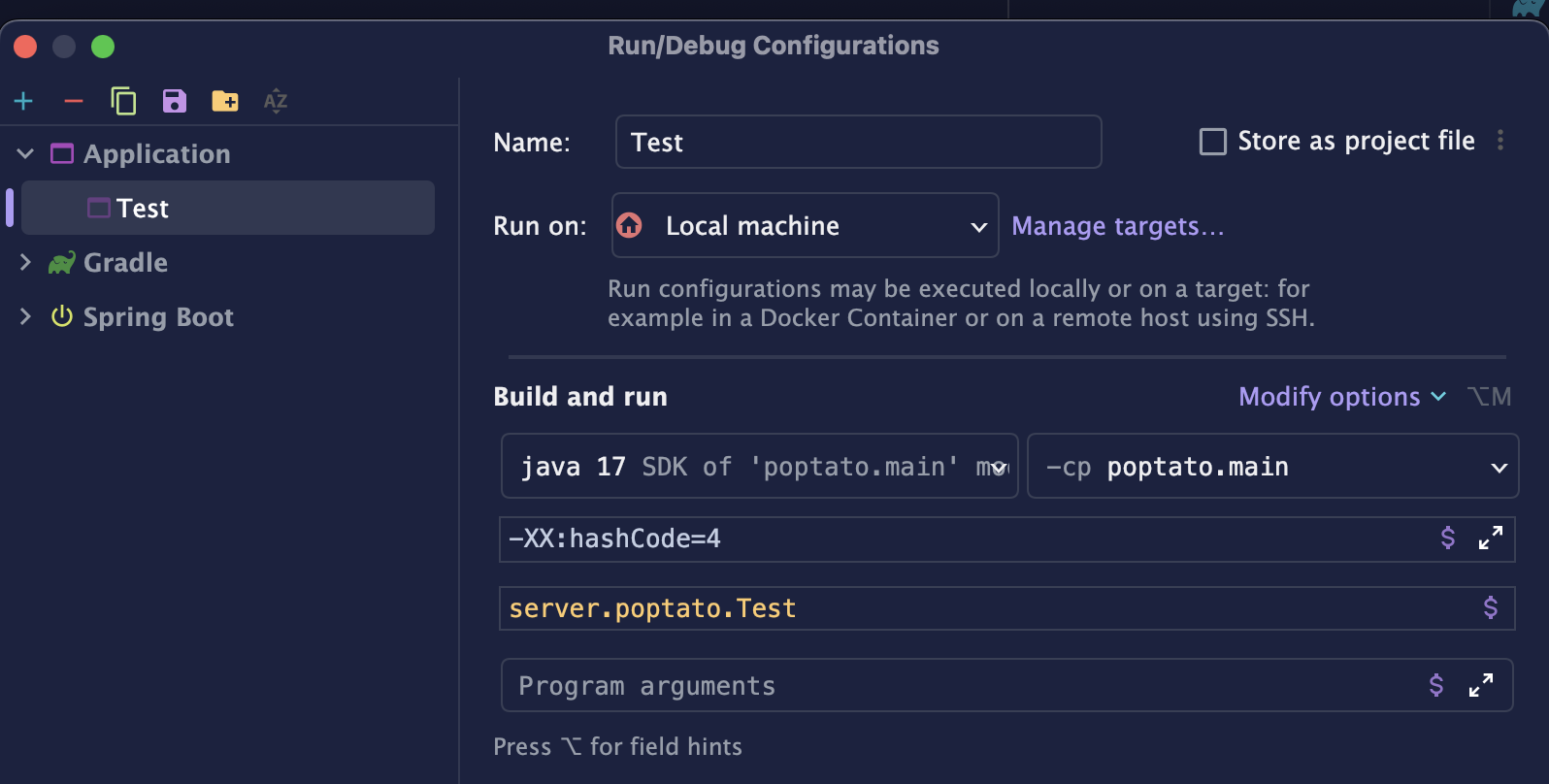
- Run 옆에서
Edit Configuration클릭
- 실행할 클래스 선택 (현 Test)
- VM Options 입력
->
-XX:hashCode=4
이렇게까지만 설정하고 실행하면 아래와 같은 에러가 뜬다.
Error: VM option 'hashCode' is experimental and must be enabled via -XX:+UnlockExperimentalVMOptions.이는 해당 hashCode 옵션이 실험적(Experimental) 옵션이기 때문에 JVM이 기본적으로 막고 있다는 의미이다.
그래서 실험적 옵션을 활성화하도록 추가 JVM 옵션을 줘야만 한다.
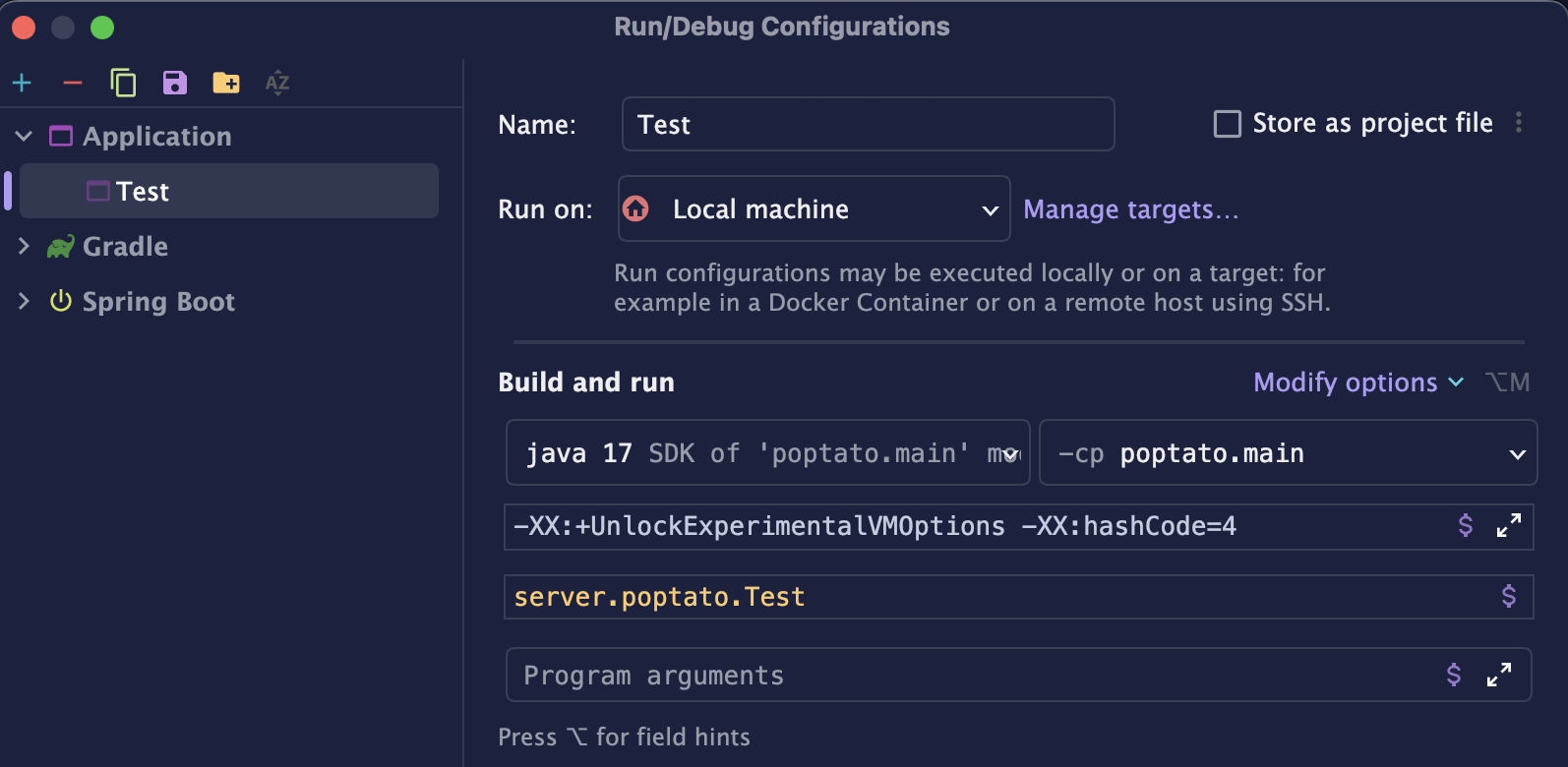
위와 같이 -XX:+UnlockExperimentalVMOptions 옵션을 앞에 추가해주자.
결과
import org.openjdk.jol.vm.VM;
public class Test {
public static void main(String[] args) {
Object obj = new Object();
// hashCode 출력
int hashCode = obj.hashCode();
System.out.println("obj.hashCode(): " + hashCode);
// JOL을 이용한 메모리 주소 출력
long address = VM.current().addressOf(obj);
System.out.println("Memory address : " + address);
// 메모리 주소를 int로 캐스팅 (하위 32비트)
int addressAsInt = (int) address;
System.out.println("Memory address (int cast) : " + addressAsInt);
// hashCode와 메모리 주소 int 캐스팅 값 비교
if (hashCode == addressAsInt) {
System.out.println("hashCode == (int) memory address : 동일합니다.");
} else {
System.out.println("hashCode != (int) memory address : 다릅니다.");
}
}
}obj.hashCode(): 266593480
Memory address : 30331364552
Memory address (int cast) : 266593480
hashCode == (int) memory address : 동일합니다.결과를 보면 Object 클래스의 hashCode() 값과, 메모리 주소를 정수형으로 캐스팅한 값이 동일한 것을 볼 수 있다!
🧑🏻💻 즉, 실제로 객체의 메모리 주소를 해시 코드로 활용하는 옵션은 존재한다.
📌 결론
-
Object.hashCode()는 JVM 구현에 따라 동작이 달라지며, 기본적으로 메모리 주소와는 무관한 값(난수, XOR-Shift 등)을 반환한다. -
hashCode()와toString()의 @뒤 값은 같지만, 이는 메모리 주소가 아닌 해시 코드의 16진수 표현일 뿐이다. -
특정 JVM 옵션(-XX:hashCode=4)을 적용하면 메모리 주소 기반 hashCode를 반환하도록 설정할 수 있다. (다만 이 옵션은 실험적이며 기본값은 아니다.)