⏰ OneTime?
원타임에 대해서 궁금하다면 아래를 참고해주세요!
⏰ OneTime 서비스 바로가기 📝 OneTime 소개글 🧑🏻💻 GitHub 📸 Instagram
🎬 서론
주변에서 OneTime을 사용하는 친구들이 요즘 들어 원타임이 느려졌다 는 말을 많이 했다 🥲
처리 속도를 보니 이는 서버에서의 문제라고 생각이 들었고 이를 해결하기 위해서 DB 성능 최적화를 해보기로 결정했다.
이번 글은 이에 대한 내용으로 이어진다.
전체 스케줄 조회 API
이전에 로깅을 개선하면서 각 API에 대한 처리 속도를 측정할 수 있게 되었다.
✅ [GET] {엔드포인트} request completed - 7786ms | status=200원타임에서 특정 이벤트에 들어가게 되면은, 참여한 모든 참여자들의 등록 스케줄을 불러오게 된다.
위는 체감상 로딩이 가장 오래 걸렸던 이벤트로, 7786ms 즉 7초 이상의 처리 속도가 걸린 것을 볼 수 있다.
이는 사용성에 있어서 심각한 문제가 된다. 유저가 이벤트에 입장할 때 7초 이상을 기다려야하기 때문이다.
초기 성능 측정
성능 측정 툴은
Grafana K6를 사용하였다.
또한 아래의 조건을 고정으로 두어 측정하였다.
- 20명의 동시 사용자가 호출 :
vus: 20
- 50번 호출 시 종료 :
iterations: 50
전체 스케줄 조회는 첫 입장 시 1번만 호출 되기에 50번만 호출해보는 것으로 제한하였다.
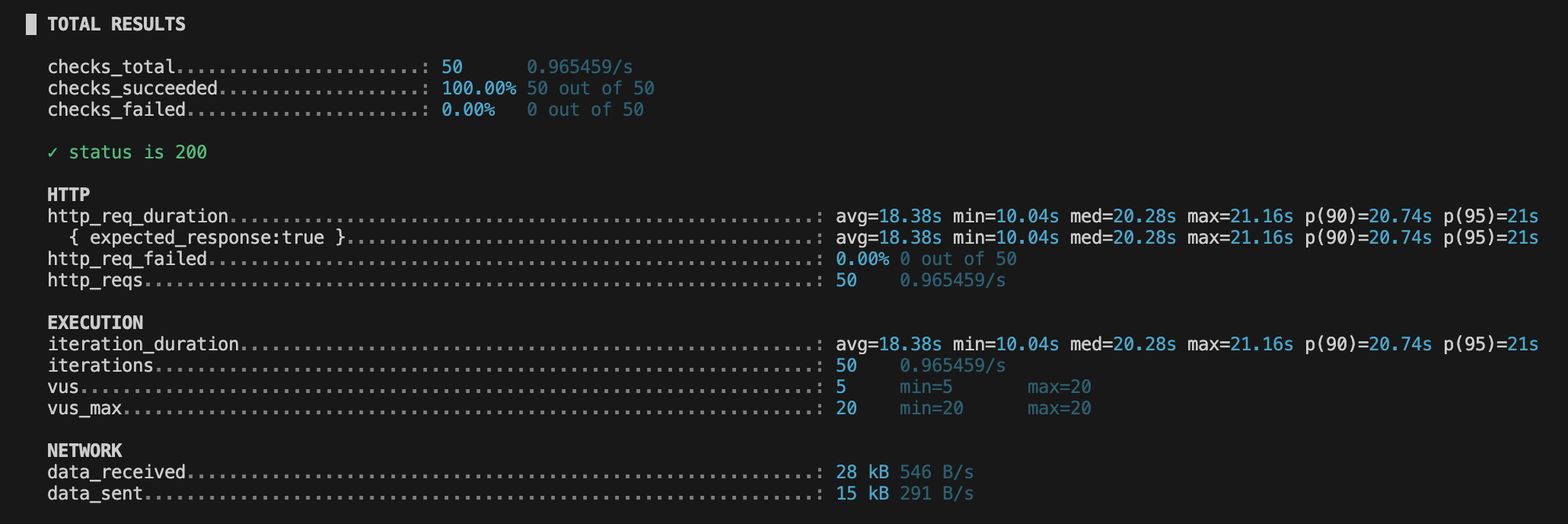
초기에는 평균 응답 시간이 18.38s 라는 매우 좋지 않은 성능을 보였다.
때문에 해당 API가 가장 먼저 해결해야 할 부분이라고 생각이 들었고, 우선 문제를 파악해보았다.
🚨 문제 1 : N+1 문제 발생
2025-05-21T19:00:06.192+09:00 DEBUG 49903 --- [nio-8090-exec-1] org.hibernate.SQL :
select
s1_0.schedules_id,
s1_0.created_date,
s1_0.date,
s1_0.day,
s1_0.events_id,
s1_0.time,
s1_0.updated_date
from
schedules s1_0
where
s1_0.schedules_id=?
Hibernate:
select
s1_0.schedules_id,
s1_0.created_date,
s1_0.date,
s1_0.day,
s1_0.events_id,
s1_0.time,
s1_0.updated_date
from
schedules s1_0
where
s1_0.schedules_id=?
2025-05-21T19:00:06.192+09:00 TRACE 49903 --- [nio-8090-exec-1] org.hibernate.orm.jdbc.bind : binding parameter (1:BIGINT) <- [387712]
2025-05-21T19:00:06.199+09:00 DEBUG 49903 --- [nio-8090-exec-1] org.hibernate.SQL :
select
s1_0.schedules_id,
s1_0.created_date,
s1_0.date,
s1_0.day,
s1_0.events_id,
s1_0.time,
s1_0.updated_date
from
schedules s1_0
where
s1_0.schedules_id=?
Hibernate:
select
s1_0.schedules_id,
s1_0.created_date,
s1_0.date,
s1_0.day,
s1_0.events_id,
s1_0.time,
s1_0.updated_date
from
schedules s1_0
where
s1_0.schedules_id=?위 로그를 보면, schedules 테이블에서 동일한 패턴의 쿼리가 반복적으로 발생하고 있음을 알 수 있다. 이는 N+1 문제가 발생했음을 나타낸다.
Map<String, List<Selection>> groupedSelectionsByDate = member.getSelections().stream()
.filter(s -> s.getSchedule() != null && s.getSchedule().getDate() != null)
.collect(Collectors.groupingBy(
s -> s.getSchedule().getDate(),
LinkedHashMap::new,
Collectors.toList()
));member.getSelections()호출 시에는 아직 데이터베이스 조회가 일어나지 않는다. 이 시점에서는 JPA의 Lazy 프록시 객체만 반환된다.- 하지만 이후 .stream().filter(…) 등의 과정에서
s.getSchedule()을 호출하게 되면, Hibernate는 각 Selection에 대해 Schedule을 개별 쿼리로 조회하게 된다. - 결과적으로 Selection이 100개라면 Schedule도 100번 조회되며, 쿼리 수가 Selection 수만큼 증가하는
N+1 문제가 발생한다.
✅ 해결 방안 : Fetch Join
@Query("""
SELECT s FROM Selection s
JOIN FETCH s.schedule sc
WHERE s.member = :member
""")
List<Selection> findAllByMemberWithSchedule(@Param("member") Member member);
@Query("""
SELECT s FROM Selection s
JOIN FETCH s.schedule sc
JOIN FETCH sc.event
WHERE s.user = :user
""")
List<Selection> findAllByUserWithScheduleAndEvent(@Param("user") User user);각각 멤버와 유저에 대해서 selections과 연관된 schedules 테이블을 한 번의 쿼리로 함께 가져오기 위한 fetch join 쿼리를 작성하였다.
유저의 경우에는 events 테이블도 필요하기 때문에 이 또한 함께 가져오도록 하였다.
📊 결과
select
s1_0.selections_id,
...
s2_0.schedules_id,
...
e1_0.events_id,
...
from
selections s1_0
join
schedules s2_0
on s2_0.schedules_id = s1_0.schedules_id
join
events e1_0
on e1_0.events_id = s2_0.events_id
where
s1_0.users_id = ?쿼리 내역을 보면, 한 번의 쿼리로 selections / schedules / events 테이블을 모두 가져오고 있다.
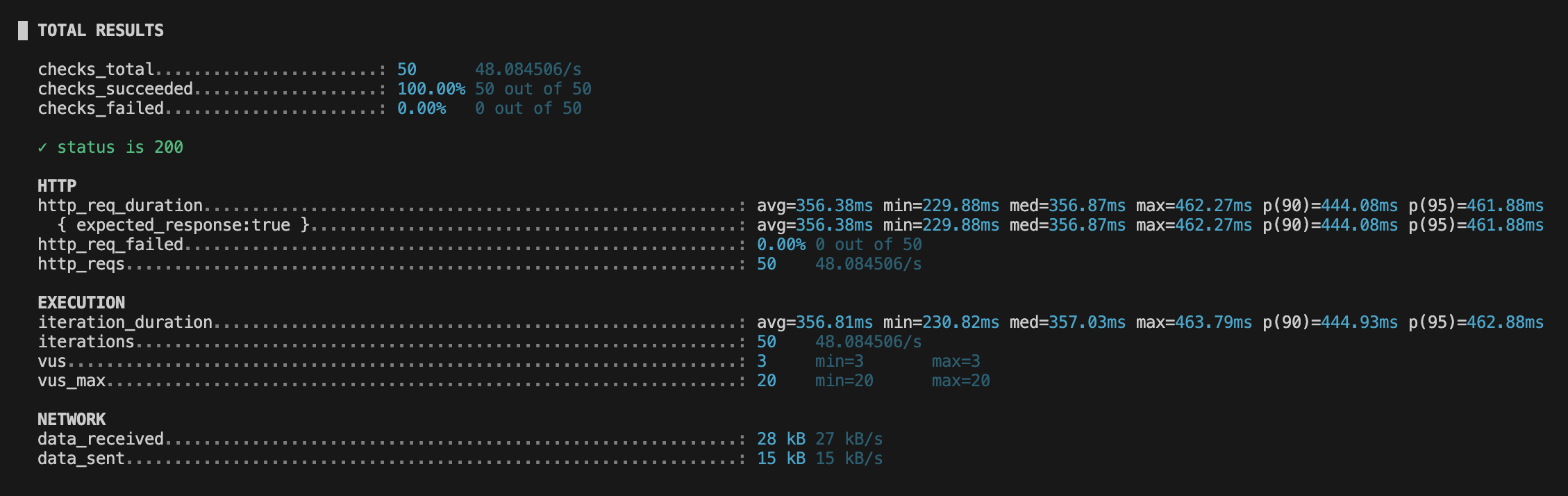
놀랍게도 N+1문제만 해결하자 평균 응답 시간이 0.35s로 개선되었다. 매번 조금씩 차이가 있지만 평균적으로 0.3 ~ 0.5초 정도만 소요되었다.
여기서 그치지 않고 더욱 개선할 수 있도록 다른 방안들도 적용해 보기로 결정했다.
🚨 문제 2 : 인덱스 미적용
[DB 인덱스에 대해서는 최근에 공부](https://bbang.dev/posts/db/index란 했기 때문에, 지금까지 적용을 해 본 적은 없었다. 하지만 공부를 하고 나니, 왜 인덱스를 걸어야 하고 & 현재 DB에서 어느 부분에 걸면 좋을지 어느정도 떠올릴 수가 있었다.
✅ 해결 방안 1 : selections 테이블에 인덱스 걸기

현재 selections 테이블은 유저와 멤버의 스케줄 선택 내역을 저장하는 조회 중심 테이블로 사용되고 있다.
INSERT는 발생하지만, UPDATE나 DELETE는 거의 없으며, API 요청 흐름상 매우 빈번한 조회(read 연산) 가 발생한다.
따라서, users_id, members_id, schedules_id 컬럼에 인덱스를 걸면 조회 성능을 획기적으로 향상시킬 수 있고, 쓰기 부하가 거의 없기 때문에 인덱스 오버헤드도 무시할 수 있는 수준이라고 판단되었다.
CREATE INDEX idx_selections_users_id ON selections(users_id);
CREATE INDEX idx_selections_members_id ON selections(members_id);
CREATE INDEX idx_selections_schedules_id ON selections(schedules_id);위 DDL을 통해서 인덱스를 직접 걸어줄 수가 있다. 걸기 전에 아래 명령어를 통해서 현재 인덱스를 확인해 보았다.
SHOW INDEX FROM selections;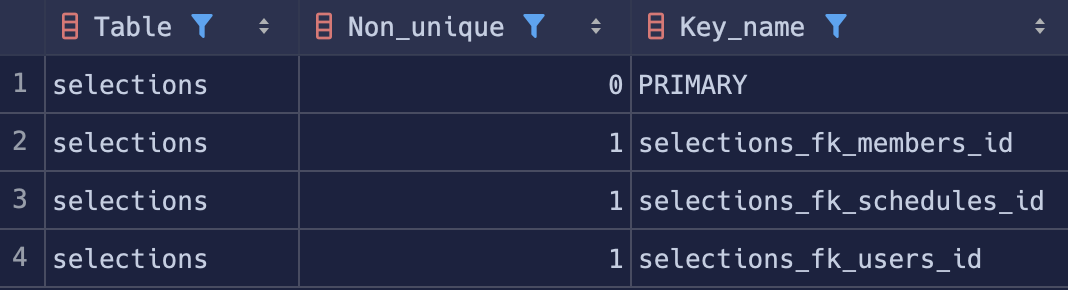
** 그런데 PK 외의 모든 FK들에도 이미 인덱스가 걸려있는 것을 알 수 있었다.**
이에 대해 찾아보니 MySQL은 FK에 대해서도 자동으로 인덱스를 생성해 준다고 한다. 참고 블로그
알다시피 인덱스를 적절하지 않게 걸게 되면 오히려 성능을 악화시킬 수가 있다. FK를 무분별하게 사용함으로써 의도치 않게 이러한 경우가 발생할 수 있을 것 같다.
🧑🏻💻 FK를 쓰지 않아야 한다는 의견도 많이 존재한다. 아마 이러한 부분들과 더불어 제약조건으로 인해서 제어하기 어려운 상황이 발생하는 것 때문인 듯 하다. 나는 아직까지는 FK를 계속해서 사용하고 있는데, 추후 공부를 한 후 방향성을 정해봐야겠다!
✅ 해결 방안 2 : schedules 테이블에 인덱스 걸기

스케줄 테이블의 경우에는 이벤트가 생성됨에 따라서, INSERT 작업이 이루어진다. 이후 이벤트를 수정함에 따라서 INSERT or DELETE 작업이 발생할 여지가 있지만, SELECT에 비해 빈도는 매우 적은 편이다.
때문에 FK를 제외한 1) date 2) day 3) time 을 대상으로 인덱스를 걸기로 결정했다.
CREATE INDEX idx_schedules_date ON schedules(date);
CREATE INDEX idx_schedules_day ON schedules(day);
CREATE INDEX idx_schedules_time ON schedules(time);하지만 여기서 유의미한 결과는 얻지 못하였다. 나는 그 이유로 해당 세 컬럼의 카디널리티가 낮기 때문이라고 판단했다.
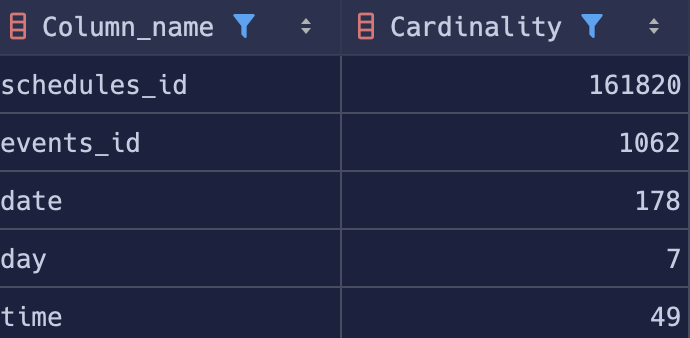
각각 178, 7, 49로 고유한 데이터들의 개수가 적은 편이며, 그렇게 된다면 DB 옵티마이저가 인덱스를 안 타는 것이 더 빠르겠는데?라는 판단을 할 가능성이 높아진다.
인덱스를 생성했는데 사용하지 않는다면 이는 오히려 불필요한 저장 공간 소모 및 쓰기 연산 시 성능 저하를 야기할 수도 있다.
복합 인덱스 사용
그렇다면 단일이 아니라 복합 인덱스를 사용하면 어떻게 될까?
조회를 할 때 date + time / day + time 의 조합으로 조회하는 경우가 있기 때문에 복합 인덱스를 걸어보았다.
CREATE INDEX idx_schedules_date_time ON schedules(date, time);
CREATE INDEX idx_schedules_day_time ON schedules(day, time);하지만 여기서도 유의미한 성능 개선을 하지는 못 하였다.
EXPLAIN SELECT * FROM schedules
WHERE date = '2025.05.13' AND time = '09:00';
EXPLAIN SELECT * FROM schedules FORCE INDEX (idx_schedules_date_time)
WHERE date = '2025.05.13' AND time = '09:00';위처럼 DB 옵티마이저의 판단 vs 강제 인덱스 사용 테스트도 진행해보았는데, date + time의 경우에는 인덱스 사용이 우세한 경우가 있었으나 대체로 큰 의미는 없었다.
🧑🏻💻 미미한 효과 때문에 인덱스를 걸기에는, 그로 인한 사이드 이펙트의 리스크가 더 클 것이라는 생각이 들어 schedules 테이블에서도 인덱스는 걸지 않기로 결정하였다.
🏁 마무리
지식의 한계를 느끼고, 조금 더 학습을 한 후에 성능 개선을 더 해보아야겠다는 생각이 들어 여기서 글을 마무리하려고 한다.
🏃🏻 앞으로 해볼 것들
- DTO Projection
- Query DSL
- 캐싱
- 정규화 / 비정규화 고려
💡 느낀 점 및 배운 점
- 테스트 상으로
18.32s -> 0.35즉 98%의 성능 개선을 할 수 있었다. 하지만 이는 N+1 문제를 해결함으로써 비교적 쉽게 얻어낸 결과이므로, 앞으로 다른 부분을 더 적용해 보고 싶다는 생각이 더 커졌다. - 성능 개선을 제대로 도전해 본 것은 처음이었는데 생각보다 재미있었다. DB는 공부할수록 유저 사용성에 긍정적인 영향을 미칠 수 있다는 점에서 좋은 것 같다.
- DB 인덱스에 대해 공부를 하고 적용을 해 보니 좀 더 이해 & 판단이 잘 되었던 것 같다. 그렇지 않았다면 무분별하게 인덱스를 적용했을 듯하다.